Ülkemizde, öğrencileri bilimsel araştırma yöntemlerini kullanmaya ve teknoloji üretmeye teşvik eden TÜBİTAK, Teknofest ve MEB gibi kurumların düzenlediği ödüllü proje yarışmaları büyük bir öneme sahiptir. Bu yarışmalar, bireylerin yaratıcı düşünme ve problem çözme becerilerini geliştirirken, teorik bilgileri gerçek hayattaki sorunlara uygulamalarına da olanak tanır.
Ancak bu tür büyük yarışmalara binlerce başvuru geldiğinde, değerlendirme süreçlerinin güvenilirliği ve jüri kararlarının tutarlılığı kritik bir sorun haline gelir. Puanlayıcılar, değerlendirme sürecinde önemli bir değişkenlik ve hata kaynağı oluşturabilir.
Peki, bir projenin değerlendirilmesinde ölçme hatalarını en aza indirmek ve en tutarlı sonuçları elde etmek için en iyi puanlama yapısı hangisidir? Tüm jüri üyelerinin tüm değerlendirme kriterlerini puanlaması mı, yoksa kriterlerin uzmanlık alanlarına göre bölünerek farklı jüri üyelerine dağıtılması mı?
İki Temel Değerlendirme Modeli
Bu soruyu yanıtlamak amacıyla, robotik-kodlama temelli proje yarışmalarının değerlendirme yapısını yansıtan simüle edilmiş veriler üzerinden iki temel Genellenebilirlik Kuramı deseni karşılaştırılmıştır:
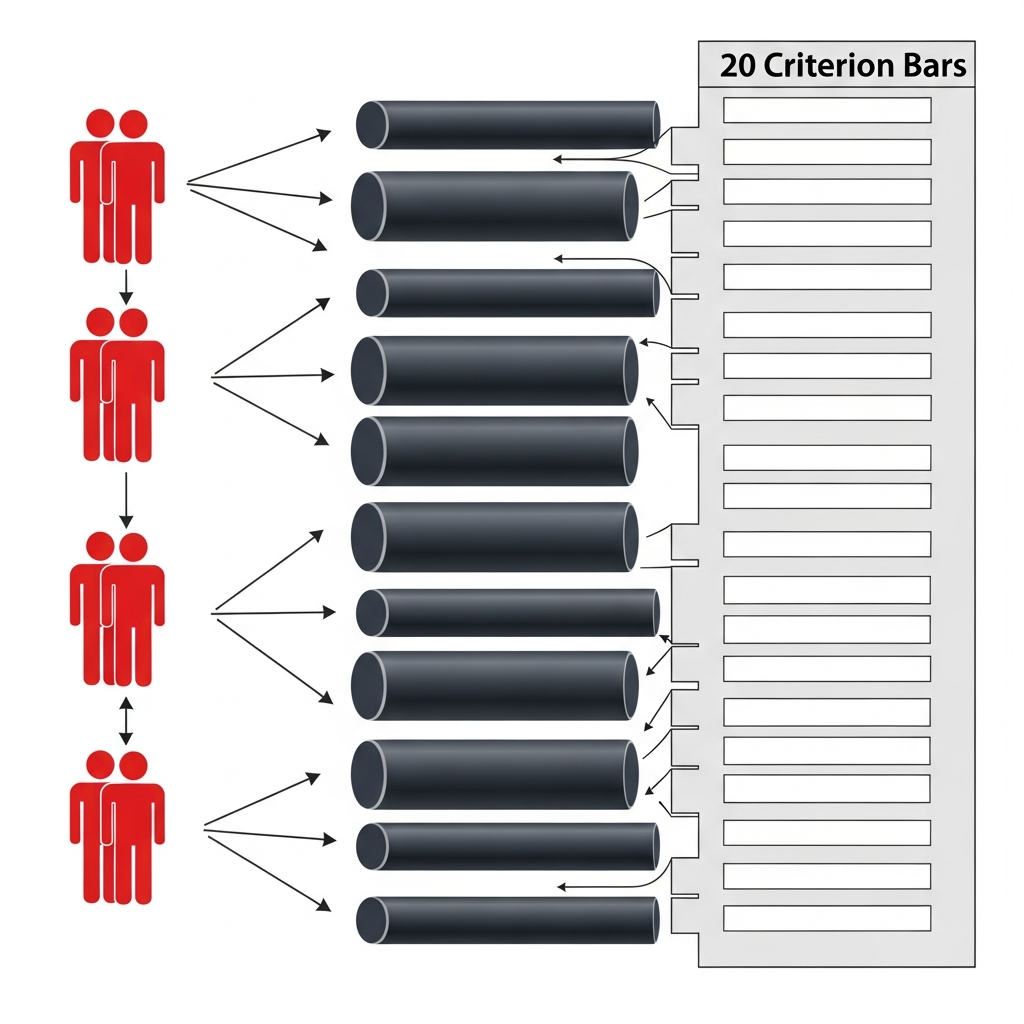
1. Çaprazlanmış Desen (b x m x p):
Bu desende, üç bilişim teknolojileri uzmanı puanlayıcının, 10 projenin tamamını, dereceli puanlama anahtarındaki 20 kriterin (madde) hepsini kullanarak değerlendirdiği varsayılmıştır.
2. Yuvalanmış Desen (b x (p : m)):
Bu desende puanlayıcılar uzmanlıklarına göre ayrılmıştır. Üç proje yazım uzmanı 7 maddeyi, üç bilişim teknolojileri uzmanı ise 13 maddeyi puanlamıştır. Toplamda altı puanlayıcı, projenin sadece kendi uzmanlık alanlarına giren kriterleri değerlendirmiştir.
Güvenilirlik Sonuçları: Çaprazlama Önde
Simülasyon sonuçlarına göre, her iki puanlama modeli de bağıl değerlendirmeler (yani projeleri sıralama veya birbirleriyle karşılaştırma) için çok yüksek güvenilirlik sonuçları sağlamıştır.
Ancak, projelerin belirli bir başarı eşiğini geçip geçmediğini belirlemek gibi mutlak değerlendirmeler için her iki modelin de yeterli güvenirlik değerlerine ulaşamadığı görülmüştür (gerekli eşik değer 0.70 iken, çapraz desen 0.45, yuvalanmış desen ise 0.27 değerini elde etmiştir).
İki temel desen karşılaştırıldığında ise, tutarlılık ve genellenebilirlik açısından önemli bir fark ortaya çıkmıştır:
- Çaprazlanmış Desen (Tüm kriterler, tüm puanlayıcılar): Daha yüksek güvenilirlik (G katsayısı: 0.96).
- Yuvalanmış Desen (Uzmanlık bazlı bölme): Daha düşük güvenilirlik (G katsayısı: 0.92).
Bu bulgular, tüm puanlayıcıların tüm kriterleri değerlendirdiği modelin, kriterlerin uzmanlık alanlarına göre bölündüğü modele kıyasla daha tutarlı ve genellenebilir sonuçlar ürettiğini net bir şekilde göstermektedir. Maddelerin uzmanlık alanlarına göre ayrılması, ölçme işlemine daha fazla hata karıştırmıştır.
Hata Kaynakları ve Pratik Öneriler
Yapılan analizler, puanlama sürecindeki en büyük değişkenlik kaynaklarının projelerin kendisi değil, puanlayıcılar arası farklılıklar (katılık/cömertlik) ve ölçülemeyen tesadüfi hatalar (residual varyans) olduğunu göstermiştir. Tesadüfi hata oranı, yuvalanmış desende daha yüksek çıkmıştır.
Değerlendirme süreçlerini organize edenler için bu çalışma önemli ipuçları sunmaktadır:
- Puanlayıcı Eğitimi Şart: Puanlayıcıların katılık veya cömertlik açısından farklı davranmaları, hata kaynağının önemli bir kısmını oluşturur. Bu nedenle, değerlendirme öncesinde puanlayıcılara detaylı ve sistematik bir puanlama eğitimi verilmesi, tutarlılığı önemli ölçüde artırabilir.
- Tüm Kriterler Değerlendirilmeli: Değerlendirme kriterlerinin uzmanlık alanlarına göre ayrılması yerine, mümkünse tüm puanlayıcıların tüm kriterleri bütüncül bir yaklaşımla değerlendirmesi, ölçme hatalarını azaltır.
- Optimizasyon: Güvenilirliği artırmak için puanlayıcı sayısını artırmak etkili olsa da, çaprazlanmış desende daha az kaynak (örneğin, 2 puanlayıcı ve 10 madde) kullanılarak da yüksek seviyede güvenirliğin yakalanabileceği belirlenmiştir. Bu durum, puanlama işlemlerinin daha az iş gücü ve daha ekonomik bir şekilde yapılabilmesine imkan tanır.
Sonuç olarak, proje yarışmalarında adil ve güvenilir bir değerlendirme için, puanlayıcıları tek bir uzmanlık alanıyla sınırlandırmak yerine, herkesin tüm resme bakmasını sağlamak en güçlü ve genellenebilir ölçme yapısını sunmaktadır.
IRMAK, M. (2025). Proje Yarışmalarında Farklı Puanlama Desenlerinin Güvenilirliği: Genellenebilirlik Kuramı ile Bir Simülasyon Çalışması. Uluslararası Öğrenen Toplum Dergisi, 2(2), 273-298. https://doi.org/10.64782/istlj.2250273-298